The Importance of Copyediting and Proofreading
February 27, 2024

Using Temp Tables to Speed Up Large Queries in SQL Server
Microsoft SQL Server is pretty good at optimizing queries when the underlying tables are in the thousands of records. But once you get into large tables (e.g. 10 million + rows) underlying your queries, things can bog down quickly.
Slow returns from SQL against large tables are not something that you just have to accept and live with. In this article, I will demonstrate how using temporary tables can drastically speed up queries against large tables.
The Tables
Our tables in question are a very straightforward design. We have a Member table that has a child table – Account – that has 2 child tables: Product and AccountBranch.
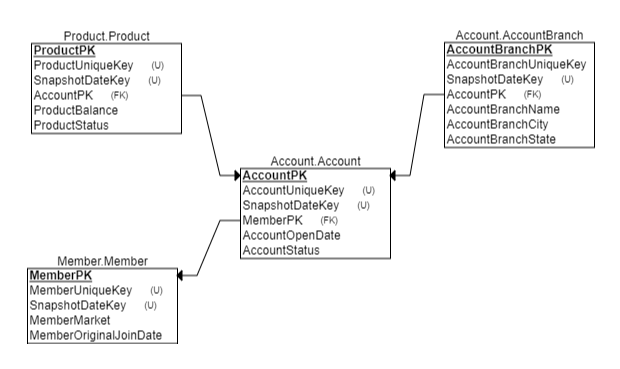
All of the data is stored as a series of snapshots within the table; therefore, there is a snapshot date in each of the tables. The snapshot date is stored as an integer in YYYYMMDD format and is named SnapshotDateKey.
Data/Machine Details
To give an idea of what we are dealing with, here are the record counts in the 4 tables:
Record Counts
- Member.Member: 549,472 (snapshot) / 87,828,158 (total)
- Account.Account: 429,051 (snapshot) / 69,856,574 (total)
- Product.Product: 969,496 (snapshot) / 59,557,373 (total)
- Account.AccountBranch: 326 (snapshot) / 53,227 (total)
Server Specs
The machine is on-premises and is adequately powered, running as a virtual machine with 36 cores, 768 GB RAM, and 13 TB of disk.
Indices
All of the tables have appropriate indices on the primary and unique keys of the tables.
Query #1: Standard Select
For the first example, we are going to write the standard SQL query using all 4 tables in the single select:
PRINT '=================Query 1'
SET STATISTICS TIME ON
SELECT m.MemberPK, m.MemberMarket, a.AccountPK, a.AccountOpenDate
, p.ProductStatus, ab.AccountBranchState
FROM Member.Member m
INNER JOIN Account.Account a ON m.MemberPK = a.MemberPK
INNER JOIN Product.Product p ON a.AccountPK = p.AccountPK
INNER JOIN Account.AccountBranch ab on a.AccountBranchPK = ab.AccountBranchPK
WHERE m.SnapshotDateKey = 20221231
SET STATISTICS TIME OFFThe results:
=================Query 1
(969496 rows affected)
SQL Server Execution Times:
CPU time = 27327 ms, elapsed time = 10660 ms.The return data set contains 969,496 records and it returned in 27,327 ms.
Query #2: Moving Account into a Temp Table
For this query, we pulled the Account data for the snapshot into a new table.
PRINT '=================Query 2'
SET STATISTICS TIME ON
SELECT a.MemberPK, a.AccountPK, a.AccountBranchPK, a.AccountOpenDate
INTO #AccountQ2
FROM Account.Account a
WHERE a.SnapshotDateKey = 20221231
SELECT m.MemberPK, m.MemberMarket, a.AccountPK, a.AccountOpenDate
, p.ProductStatus, ab.AccountBranchState
FROM Member.Member m
INNER JOIN #AccountQ2 a ON m.MemberPK = a.MemberPK
INNER JOIN Product.Product p ON a.AccountPK = p.AccountPK
INNER JOIN Account.AccountBranch ab on a.AccountBranchPK = ab.AccountBranchPK
WHERE m.SnapshotDateKey = 20221231
SET STATISTICS TIME OFFThe temp table isn’t indexed in any way and only contains the information needed for the second query.
The results are surprising:
=================Query 2
SQL Server Execution Times:
CPU time = 1683 ms, elapsed time = 574 ms.
(429051 rows affected)
SQL Server parse and compile time:
CPU time = 90 ms, elapsed time = 90 ms.
(969496 rows affected)
SQL Server Execution Times:
CPU time = 6440 ms, elapsed time = 11543 ms.The total CPU time for this query is (1683 + 90 + 6440) = 8213 ms. That is a 70% reduction in time.
Query #3: Using 2 Temp Tables
For the 3rd iteration, we place both the product and account data into temporary tables.
print '=================Query 3'
SET STATISTICS TIME ON
SELECT a.MemberPK, a.AccountPK, a.AccountBranchPK, a.AccountOpenDate
INTO #AccountQ3
FROM Account.Account a
WHERE a.SnapshotDateKey = 20221231
SELECT p.AccountPK, p.ProductStatus
INTO #ProductQ3
FROM Product.Product p
WHERE p.SnapshotDateKey = 20221231
SELECT m.MemberPK, m.MemberMarket, a.AccountPK, a.AccountOpenDate
, p.ProductStatus, ab.AccountBranchState
FROM Member.Member m
INNER JOIN #AccountQ3 a ON m.MemberPK = a.MemberPK
INNER JOIN #ProductQ3 p ON a.AccountPK = p.AccountPK
INNER JOIN Account.AccountBranch ab on a.AccountBranchPK = ab.AccountBranchPK
WHERE m.SnapshotDateKey = 20221231
SET STATISTICS TIME OFFWe see a further reduction in the time:
=================Query 3
SQL Server Execution Times:
CPU time = 1733 ms, elapsed time = 608 ms.
(429051 rows affected)
SQL Server Execution Times:
CPU time = 2034 ms, elapsed time = 635 ms.
(969496 rows affected)
SQL Server parse and compile time:
CPU time = 124 ms, elapsed time = 124 ms.
(969496 rows affected)
SQL Server Execution Times:
CPU time = 3733 ms, elapsed time = 10774 ms.The total time for the third iteration is (3733 + 124 + 2034 + 1733) = 7613 ms., or 73% reduction in the time of the original query.
Consistent Drop in Time
Applying this strategy across the breadth of the client SQL has yielded incredible time savings. Some queries have dropped from hours to under seconds. The majority of the queries have seen run times drop from 50 to 75%.
When the team first encountered this, we concluded it had to be attributable to something on the tables: a lack of appropriate indexing, fragmentation, or any of other common causes of slow performance.
Extensive investigation has led us to conclude that the SQL engine doesn’t limit the tables before combining them for the final result set. It appears that in the above queries, the joins from Member down are done before the snapshot date filter is applied.
Using Table Variables or CTEs
Given a machine with enough memory, table variables or CTEs could also work in this scenario. However, since these are in-memory objects, you lose the ability to index them should it be needed for the boost of speed.
In the above examples, using table variables or CTEs instead of temp tables was just as performant.
Summary
When working with large tables using T-SQL, you can boost the performance by reducing the size of the component tables by using temporary tables.

Laura MossCore Contributor
Laura Moss is a senior software engineer with Marathon Consulting. As a data wrangler, she specializes in data warehouse architecture and moving data between systems. Her inbox is always empty.